Quick Links
Frequently-asked questions
»
Questions
Text in bold is suggested wording and text is italics is commentary on the answer.
First, it is important to remember to answer each part of the question. Make it clear which part of the question you are answering by using the question parts indicated (a, b, c and d). It is useful to start each part of your answer on a new page, allowing you to add extra detail after your initial answer.
This part of the question is clearly 'bookwork' and is asking you to reproduce lecture material on good data design. In fact, looking ahead you can see that the question is about functional dependency and data normalisation, which gives a clue on answering this part of the question.
A data design should always be checked after creation to ensure that it is at least adequate for the system being designed and supports the system in meeting the user requirements.
The statement so far is basically an obvious response to the question, but says nothing about the real point the question is aiming to get to. You therefore need to say more.
As far as data is concerned, it is also necessary to check the quality of the design- it is not sufficient simply for data to meet the current user requirements- it is also necessary that it does this both efficiently and is structured in such a way as to avoid problems using the data in the future.
When considering data, there are three tests which can be applied:
- can you insert data without problems
- can you amend data without problems
- can you delete data without having undesirable side effects
Where these tests fail, you have what is known as an insertion, update or deletion anomaly.
This is sufficient to get half the available marks, but you can get full marks by explaining the problems of insertion, update or deletion anomalies by giving examples.
An insertion anomaly arises when you have variable length or repeating data; for example where a data structure contains details of an invoice and the goods sold.
INVOICE (invoice-number, (product-id))
| INV001 | P00123 | ||
| INV002 | P00567 | P00123 | P10222 |
If the data structure to support this entity allowed 3 product-ids, you have a problem when coming to add a 4th product to invoice with invoice-number INV002.
An update anomaly occurs when you have data which is repeated. The problem is that a programmer might only update the first occurrence of the data and not the subsequent data. For example, in the following table:
INVOICE (invoice-number, customer-reference, customer-name...)
| INV001 | C175 | SMITH | ... |
| INV002 | C617 | BLOGGS | ... |
| INV003 | C175 | SMITH | ... |
| INV004 | C183 | FIKES | ... |
if customer C175 changed his/her name to WILSON, there is the danger that the second occurrence of customer C175 would not be updated.
A deletion anomaly occurs when you have a structure such as that shown immediately above. If you delete invoice INV004, you loose the information that customer C183 is the customer FIKES (this is assuming it is not stored elsewhere).
For this part of the question you can give the standard text book definition as follows.
For two attributes A and B in a given table, A is functionally dependent upon B if for every valid instance, the value of B determines the value of A.
This part of the question is concerned with developing a functional dependency diagram.
It is important when developing the functional dependency diagram that you check your diagram against the data shown in the question.
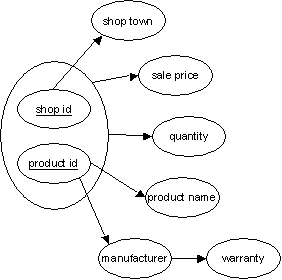
shop-town is clearly dependent upon shop-id and product-name and manufacturer are clearly dependent upon product-id.
sale-price is a potential source of error, because intuition says sale-price is functional dependent upon product-id. However if you look at the data you can see that X257 Camcorder is sold for £450 in shop A5 and for £495 in shop M7. Notice also that the text says "The database shows how many products are available for sale in each shop, together with the sale price of the product in each shop". This confirms that a product is potentially sold for a different price at different shops. Therefore the functional dependency link to sale-price must come from the joint shop-id and product-id key fields. Similar arguments apply to quantity.
This part of the question is concerned turning the entity SHOP in to third normal form. It is clearly related to part c of this question and your answer should make explicit reference to the functional dependency diagram shown in part c.
Before answering each section of this question, you should state clearly what the issue is and what first normal form (second, third etc.) is.
1NF: First normal form states that an entity should have now repeating fields. If there are repeating fields, there may be insertion anomalies when adding repeated data to the entity.
Then explain how to get the entity into 1NF.
To obtain a structure in 1NF, you must remove the repeating attributes from the entity and place it in a new entity. You must create a composite primary key in the new entity comprising the primary key in the original entity, plus one other attribute which will indicate the occurrence of the repeated data (1st occurrence, 2nd, 3rd etc.)
SHOP (shop-id,
shop-town)
ITEM (shop-id, product-id, product-name, manufacturer, warranty, quantity,
sale-price)
The structures SHOP and ITEM are now in 1NF. ITEM is the new structure. The attribute shop-id in ITEM is brought from the original SHOP entity, whilst product-id is sufficient to make the composite key unique provided that each product has a unique identifier.
The last part of this statement is important as it explicitly states the assumption being made and which validates your answer.
2NF: Second normal form states that an entity must have all non-key fields dependent upon the whole of its primary key. This means that by definition any structure with a simple primary key (i.e. made up from one attribute) is automatically in 2NF, such as SHOP.
However ITEM has a composite primary key and a check must be made to ensure its non-key attributes are dependent upon the key and the whole of the key.
From the functional dependency diagram in part c, it is clear that sales-price and quantity are both dependent on shop-id and product-id. But manufacturer and warranty are only dependent upon product-id.
Therefore we need to remove the attributes which are only dependent upon part of the primary key into a structure of their own. This is shown as PRODUCT below. product-id becomes the primary key of this new table.
SHOP (shop-id,
shop-town)
ITEM (shop-id, product-id, quantity, sale-price)
PRODUCT (product-id, product-name, manufacturer, warranty)
Finally you need to check for 3NF. Remember you should check all tables.
3NF: Third normal form states that there must be no functional dependency between non-key fields.
Taking each structure in turn, we can check for dependencies. SHOP has only one non-key field so must be in 3NF. In ITEM, there is no dependency between quantity and sale-price, so it is in 3NF.
However in PRODUCT, there is a dependency between manufacturer and warranty (as shown in the functional dependency chart in part c).
Remember to mention any assumptions.
This is because we assume that a warranty is associated with a manufacturer, rather than a product or shop. Checking the sample data for example, you can see that Suzuki has a warranty of 24 months.
Now convert to 3NF.
Therefore, to create a 3NF structure, we must remove the dependent attribute from PRODUCT and create a new structure. In the new structure, the fields are the dependent attribute (warranty) and the primary key is the attribute on which it is dependent (in this case manufacturer).
SHOP (shop-id,
shop-town)
ITEM (shop-id, product-id, quantity, sale-price)
PRODUCT (product-id, product-name, manufacturer)
WARRANTY (manufacturer, warranty)
Finally, it is worth restating the rules for 3NF.
So to create a structure in 3NF, we must ensure that each structure:
- has no repeating fields
- has non-key attributes which are dependent upon the whole of the primary key
- and only the primary key.
To obtain full marks, you must also add:
It should be noted that 3NF is the commonest form of normal forms, but other forms such as 4NF and 5NF do also exist.
Quick Tips
|
Details correct as on 28th July 2005 |
Home | Contact Us| Legal |